Modern platform engineering teams often assemble “DIY” control planes for their Products using open-source building blocks: Kubernetes for the runtime, Terraform for infrastructure provisioning, and Argo CD for continuous deployment. This stack promises cloud-agnostic flexibility and full control. But as many CTOs and platform VPs have learned, stitching these tools together into a robust control plane is hard.
This post kicks off a three-part series exploring the architectural and operational challenges of building SaaS control planes with Kubernetes, Terraform, and Argo CD, and how Omnistrate helps solve them without a rip-and-replace approach.
- In this post, we examine why teams go DIY and where the complexity creeps in.
- In Part 2, we’ll show how this plays out in the real world using a Redis SaaS / BYOC.
- In Part 3, we’ll explore how Omnistrate augments your stack, simplifying tenant lifecycle, self-serve deployments, infrastructure management, billing, and Day-2 operations at scale.
We’ll dive deep into why teams take the DIY route, the architectural and operational challenges that emerge (BYOC, multi-cloud, tenant provisioning, day-2 ops), and real examples of the complexities in coordinating Terraform, Argo CD, and Kubernetes. We’ll then explore how Omnistrate can seamlessly slot into this landscape to alleviate these pains – without a rip-and-replace – by handling tenant lifecycle, abstracting cloud complexity, and providing SaaS niceties like metering, upgrades, and compliance out of the box.
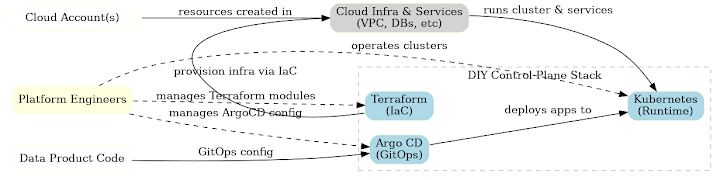
Why Platform Teams Build DIY Control Planes with Kubernetes, Argo CD & Terraform
Platform engineering teams are under pressure to deliver internal platforms and SaaS offerings faster than ever. It’s no surprise many turn to battle-tested tools to assemble their own control planes:
-
Kubernetes is the de facto runtime for containerized data products. Its orchestration capabilities and ecosystem allow teams to run databases, analytics engines, or AI model services at scale on any cloud or on-prem. By using Kubernetes, teams get a consistent environment to deploy their product across dev, staging, and customer environments.
-
Terraform brings Infrastructure-as-Code (IaC) to provision the underlying cloud resources. With Terraform, engineers can automate creation of networks, managed databases, Kubernetes clusters (EKS/GKE/AKS), load balancers – the plumbing needed for their product – in a repeatable way. Terraform’s broad provider support means the same language can spin up infra on AWS, GCP, Azure, or even on-prem. This is appealing for maintaining multi-cloud flexibility and avoiding cloud lock-in.
-
Argo CD provides GitOps-driven continuous delivery of applications onto Kubernetes. By treating Git as the single source of truth for Kubernetes manifests (or Helm charts, Kustomize, etc.), Argo CD ensures that application deployments are declarative and auditable. Any config change in Git can automatically sync to all clusters, keeping environments consistent. This meets the DevOps ideal of automated, continuous deployment for microservices and data workloads.
In theory, these three tools complement each other: Terraform provisions the infrastructure, Kubernetes runs the workloads, and Argo CD deploys the application code. Each is declarative, enabling a GitOps workflow across infra and apps. It’s easy to see why teams assemble this stack as a DIY control plane – it promises full control over the environment and tech-stack consistency across clouds.
Typically, platform engineers use Terraform to provision cloud infrastructure (VPCs, databases, clusters) in each environment, and Argo CD to deploy and sync application workloads onto Kubernetes. While this provides flexibility and leverages declarative tools, it also means managing disparate pipelines and state for infrastructure versus applications.
Also, engineering leaders often feel that these open tools are widely adopted standards (Kubernetes and Terraform skills are common) and can be adapted to their unique needs. Using open-source components avoids vendor lock-in and licensing of proprietary platforms. And early in a product’s life, a quick combination of Terraform scripts plus some Kubernetes manifests behind a UI may seem like the fastest path to “SaaS-ify” an on-prem product. The DIY route offers perceived agility – teams can start now without waiting for budget approval or features from a vendor.
There’s also an ethos of control: owning the deployment tooling means you’re not constrained by another platform’s assumptions. Many platform engineers pride themselves on building internal tooling; assembling a bespoke control plane can feel like building exactly what the organization needs. It’s akin to how early SaaS pioneers built everything in-house – if you have the skills on staff, why not build it yourself?
However, as we’ll see next, this path is strewn with landmines. What works for a single environment or a handful of customers can buckle under the complexity of real-world SaaS demands.
Challenges with the DIY Control Plane Approach
For all its initial appeal, a homegrown control plane built on Kubernetes + ArgoCD + Terraform begins to strain as your product and customer base grows. Platform leaders should be aware of several key architectural and operational challenges that tend to emerge:
Day-0 architectural challenges
Let’s dig deeper into some of the architectural challenges with the above approach:
One of the core functions of any SaaS control plane is tenant provisioning: when a new customer signs up, how quickly (and reliably) can you spin up their isolated environment? With Kubernetes+Terraform, this typically involves a sequence like:
- Infrastructure provisioning (Day-0): Use Terraform to create cloud resources for the tenant – e.g. a new Kubernetes cluster (or a namespace on a multi-tenant cluster), databases, message queues, object storage buckets, etc. This step must handle variations per cloud (for multi-cloud) and ensure naming/quotas don’t conflict.
- Application deployment: Once infra is ready, deploy the application components to the Kubernetes cluster. This may be done by registering a new Argo CD Application manifest pointing to the customer’s config (or using Argo CD’s App-of-Apps or ApplicationSet to template many instances). The app deployment might include loading initial data or config for that tenant.
- Configuration & access: Set up DNS entries, SSL certificates, credentials, and any cross-connection needed (e.g. if the tenant’s cluster needs to reach an external data source). Often some of these come from Terraform outputs (like a DB connection string) and need to feed into app config – meaning you must plumb Terraform outputs into Kubernetes manifests (not trivial to do cleanly).
- Onboarding steps: Enable user accounts, generate API keys and send the customer the endpoint/credentials to access their environment.
Coordinating these steps is fragile when using separate tools. Terraform doesn’t natively wait for Argo CD, and Argo CD isn’t aware of Terraform. So teams script glue code or pipeline logic (e.g. in Jenkins, GitHub Actions, or custom operators) to kick off Terraform, then inject output into a Helm values file, then let Argo deploy, etc. This is error-prone – if any step fails, you have to reconcile partial states across two systems. Without careful orchestration, you might deploy an app expecting a database before the DB is fully up, or vice-versa.
Even offboarding a tenant is tricky. Terraform can destroy resources, but you better orchestrate it in the right order (e.g. tell Argo to delete Kubernetes objects first so the app stops cleanly, then Terraform destroys the cluster). One mistake and you could leave orphaned cloud resources (cost leak) or, worse, remove something still in use.
Another challenge is sheer scale: if you land 50 new customers, do you run 50 separate Terraform applies and Argo app bootstraps manually? Platform teams often invest in building an internal self-service UI or automation to handle this volume. Every new tenant is like deploying a mini-instance of your product – it needs to be automated to be efficient. The typical pattern here is to set up a GitOps workflow that has each customer setup tracked as a separate folder in a Git repo much like files.
Different customers have different deployment needs
The first few customers may seem like a victory, but soon it becomes clear that different customers have slightly different needs. They have varying infrastructure requirements, pricing structures, and workloads that need to be tuned differently. While new customers are signing up with newer requirements ever-so slightly different from the previous one, the application team is constantly changing the application and its behavior, the business is learning or making minor pivots to find better product-market fit, cloud providers are constantly bringing new hardware and cloud services to life making some of the old assumptions obsolete, the world around us is evolving with new tech trends or regulatory requirements.
As these things are happening, the team makes the last ditch attempt to somehow manage the chaos until eventually no one knows and the team's understanding starts to drift from the core reality, mistakes start to happen, customers start losing trust and it’s chaos everywhere. No one knows all the variations used across different customers. Making changes, testing and rolling it out becomes a very expensive process. It slows down business to try new product experiments or to roll out new changes quickly or adopt newer generation hardware from cloud providers in an automated fashion. For experienced people, this is not a fiction and they have seen it play out.
Even after all this, your customers don't have a mechanism to self-serve their onboarding, or their provisioning. They have to file a ticket, wait for the support team to send the request to the platform, who will click through things or run some scripts to turn around in a few days at best. Gone are the days, when we can ask customers to wait for days before they can try – all of that is just lost customers or lost revenue for nonuse.
Then, the same challenge exists every time they want to make any change to their deployment. In case, your customers have an unplanned event and need to do something quick, they have to file a P0 ticket and someone on your team has to wake at odd-hours to handle those requests. There are no mechanisms for your customers to self-serve those updates or customizations through REST APIs or CLI or some UX portal.
Let’s say you build something to make it self-serve for your customers. Now, imagine if two users are provisioning at the same time? Or the same user provisioning multiple deployments at the same time? - can your system handle all sorts of synchronization from the first principles, guard against failures, and seamlessly recover from them? What about the concurrent user operations on the same deployment, ex - your user issues an update operation while the background scale-down operation is happening, can your system handle the state without proper synchronization?
Now, some variations are beyond what customers can configure ex - different subscription plans with different feature sets and security requirements, and there is usually no-size-fit-all. The enterprise customers are ready to pay for the cost but they usually have strict guidelines on security controls and compliances. On the other hand, the startup segment may be forgiving on some of those requirements but are looking for the cost-effective alternative. You might have other requirements in the middle to balance the two. How do you now serve both of these segments while allowing customers to gradually graduate from one plan to another? This will require some surgery by the platform teams to either move the infrastructure or recreate the infrastructure, migrate the data, validate everything is okay. Now, how will you do that with no downtime, it will require a lot of coordination and crucial time for your engineers.
Here is another example: when you have a handful of customers, you can keep all the pricing conversations in mind but as you scale, you might try different pricing models, or pricing structure. Moreover, your customer needs may change over time. Your application may run into an issue and you may want to issue some credits. You need a proper place to keep track of these history, you need a mechanism to try out different pricing models/rates, you need a visibility into margins per tenant, you need a mechanism to offer flexibility to your customers to choose the payment channel of their choice (Stripe, cloud marketplace, Vercel, direct, etc).
Finally, internal teams will need some sort of visibility into tenants, deployments, their cloud accounts, their deployment configurations, their infrastructure, their subscriptions, their account history etc. Teams often build some sort of custom scripts but scaling them as your team is growing and requirements are changing in a non-standard way often leads to high maintenance cost, developer onboarding to learn all the custom tooling and continuing to maintain them every time new customer requirement comes up or business wants to do some experiment.
Some teams claim their application is special and that the above complexity is unavoidable. However, good teams recognize this early, acknowledge the mistake, and realize that building a control plane is like building an operating system for the cloud. Stitching three open-source tools together is as effective as a graduate school project. At Confluent, we tried the same way only to revert 3-months down the line to build a proper control plane that took several dozens of engineers and years of development, a luxury most startups and platform teams don’t have.
Multi-Cloud and “Bring Your Own Cloud” (BYOC) Complexity
Many data-product or AI-product companies soon face customer demands for flexibility in where the product runs. Enterprise clients might say, “We love your SaaS, but for compliance, it must run in our cloud (or on Azure instead of AWS).” Supporting multi-cloud deployments or a BYOC model (Bring Your Own Cloud/Account) is a major undertaking with a DIY stack.
With Terraform alone, handling multi-cloud means writing and maintaining separate IaC modules for each provider (or complex conditional logic in modules). Even if Terraform supports both AWS and Azure, you end up duplicating effort to account for cloud differences – e.g. AWS security groups vs. GCP firewall rules. Kubernetes offers a consistent layer for your app, but provisioning and networking those clusters in each cloud is inherently cloud-specific. Cross-cloud inconsistencies can creep in, undermining the “write once, deploy anywhere” ideal.
BYOC amplifies this even further. In a BYOC model, your control plane (in “your cloud”) must deploy and manage product instances inside each customer’s cloud account, whether AWS, Azure, or GCP. This strong isolation is great for customers but creates exponential operational complexity for your platform team.
Now your platform must provision and operate infrastructure in accounts you don’t control. Each new customer might require setting up a dedicated VPC, Kubernetes cluster, and database in that customer’s cloud account. Your Terraform code needs to assume roles or use federated credentials to deploy to external accounts, and you must establish trust and networking in a secure way. Teams often resort to complex automation to handle cross-account AWS IAM roles or service principals on Azure. As Omnistrate’s experts note, deploying a fully isolated stack per tenant in their own account provides strong security but “comes with a huge operational overhead,” requiring management of potentially thousands of environments without opening holes in customer firewalls.
Networking is a big headache here: How do your control-plane components (say, a central Argo CD instance or CI pipeline) even reach a Kubernetes API in a customer’s locked-down VPC? Some teams set up jumphosts or pry open firewall ports, which raises security flags. The recommended approach is often a reverse connection – e.g. an agent in the customer environment phones home to your control plane. Implementing that securely (TLS, token auth, etc.) is a project in itself. In short, DIY multi-cloud/BYOC support tends to balloon into a complex software project – beyond just writing Terraform scripts.
Day-2 Operations (Upgrades, Patching, Support)
For Day-2 operations – everything that happens after a tenant is up and running – is where a DIY control plane is even more clueless:
-
Upgrades & Patching:
- Shipping a new version of your data product often means updating application code and possibly the infrastructure. For example, a new feature might require an extra microservice (needing a new deployment on K8s) and maybe a new database table or cache (cloud infra). Rolling this out to dozens of tenant environments in sync is daunting. With Argo CD, you can push app updates to all clusters, but if there’s an infra change, you also have to run Terraform for each tenant. Coordinating schema migrations or ensuring no downtime across tenants might force you into serial or batched rollouts.
- Teams end up writing custom scripts to loop over each tenant, apply Terraform, then trigger Argo deployments – reinventing a poor man’s orchestration system. One missed step or conflict with the previous changes, and a fraction of customer environments drift from the desired state. It’s no wonder many organizations find their homegrown automation “too complex to maintain” and eventually adopt a more managed control plane approach.
- Then, each of your customers wants to have control over the maintenance window when the upgrade is scheduled, requiring heavy coordination across teams.
- In addition, if a P0 application bug is found or there is a critical security issue, every time your team has to scramble to figure out the state of each deployment, coordinate with each of the customers, and make sure all the clusters are upgraded in a short period of time.
- Finally, as your team is growing, in order to test changes, you will need multiple developer environments. However, managing and maintaining developer environments cost-effectively that represents production is a challenge in itself.
-
Monitoring & Incident Response:
- With potentially hundreds of Kubernetes clusters or namespaces (one per tenant), getting a unified view of system health is non-trivial. You’ll need centralized logging and monitoring that aggregates across all those environments. You might deploy Prometheus+Grafana in each cluster, or run one central monitoring stack, scraping metrics from all – either way, it’s extra engineering.
- But even then, it only provides an application view. When something goes wrong at 2 AM (“Deployment X’s is failing”), on-call engineers must dig through multiple layers (app logs in Argo, cluster status, cloud infra metrics) across potentially multiple cloud providers. The fragmented tooling (CloudWatch for AWS infra, Argo CD for apps, etc.) makes it hard to have one pane of glass and answer basic questions like who is the tenant, what application version were they running, whats their infra setup view, when was the last change made, has any of the cloud dependency failed, etc. This drives up MTTR and operational load.
- Your customers will often ask for an SLA before putting production workloads but you still have no protection against datacenter failures or correlated failures and hope is not a strategy.
- Then, there are things that maybe technically outside the SLA but affects the customer experience, ex - your customer applications to be able to talk to your stack. Just because your stack is up is not the end of the story, you have to make sure that your customers can reach your application stack and you have to detect and recover from them.
- Finally, what about the disaster scenarios? Can you recover from regional failures? Can your control plane recover from regional failures? How long will it take to recover? Have you ever tested it?
-
Cost and Resource Management:
- In a bring-your-own-cluster model, you might have dozens of EKS clusters idling for small customers. Are those right-sized? Without automation, you might be misallocating resources and burning money.
- Ideally you’d have auto-scaling to zero for unused environments, multi-tenant pooling, etc. Kubernetes can auto-scale pods, but scaling entire tenant clusters or turning them off when idle for stateful workloads without impacting application behavior is something you’d have to build from the ground up.
- What if you can make a better decision on scaling based on application metrics than CPU-load? What if you want to leverage spot instances or reserved instances? What if you want to take advantage of GPU slicing or multi-tenancy? – all of this is extra engineering
- Even after all this, you are completely blind on basic per-tenant usage and its trajectory, margins, cloud costs per tenant, something Terraform or Argo do not provide out-of-the-box
-
Security & Compliance: SaaS providers need to meet standards like SOC 2, GDPR, etc. That means you have to enforce certain configurations everywhere (e.g. all S3 buckets encrypted, all databases have backups and PITR enabled, role-based access control on each cluster, audit logs for every administrative action). Ensuring every one of your 100 Terraform-provisioned environments meets these policies is a huge task. Often scripts are written to run checks, or policy-as-code tools like Open Policy Agent are integrated – again, more pieces to glue together. The DIY approach gives you freedom but also responsibility for every aspect of security. It’s easy to miss something and end up with a compliance gap
Crucially, these challenges tend to compound. As I mentioned above, building a control plane in-house is akin to building a cloud operating system – a “massive, multi-year effort with no guarantee of success”. Many startups underestimate this and end up with rigid architectures and incomplete features after years of work. Terraform scripts and a UI might work for a pilot, but scaling that to an enterprise-grade SaaS is like “building a skyscraper on sand”. In fact, a McKinsey report found over 70% of in-house engineering projects fail to meet flexibility and scalability goals, forcing rewrites in 3-5 years. The DIY control plane often hits a wall as the product scales, stalling the entire company’s growth as migrating away to another control plane is non-trivial. Hence, the successful companies like AWS, Confluent, Databricks recognized this much earlier in the journey and had to invest in building and operating a proper control plane with hundreds of engineers.