Organizations today face mounting pressure to deliver AI capabilities while managing exploding infrastructure costs. GPU expenses can easily consume your AI budget, yet most organizations are unknowingly wasting massive amounts of these expensive resources through inefficient allocation strategies.
The solution lies in GPU sharing strategies that transform expensive, underutilized hardware into highly efficient, multi-tenant resources that serve multiple workloads simultaneously.
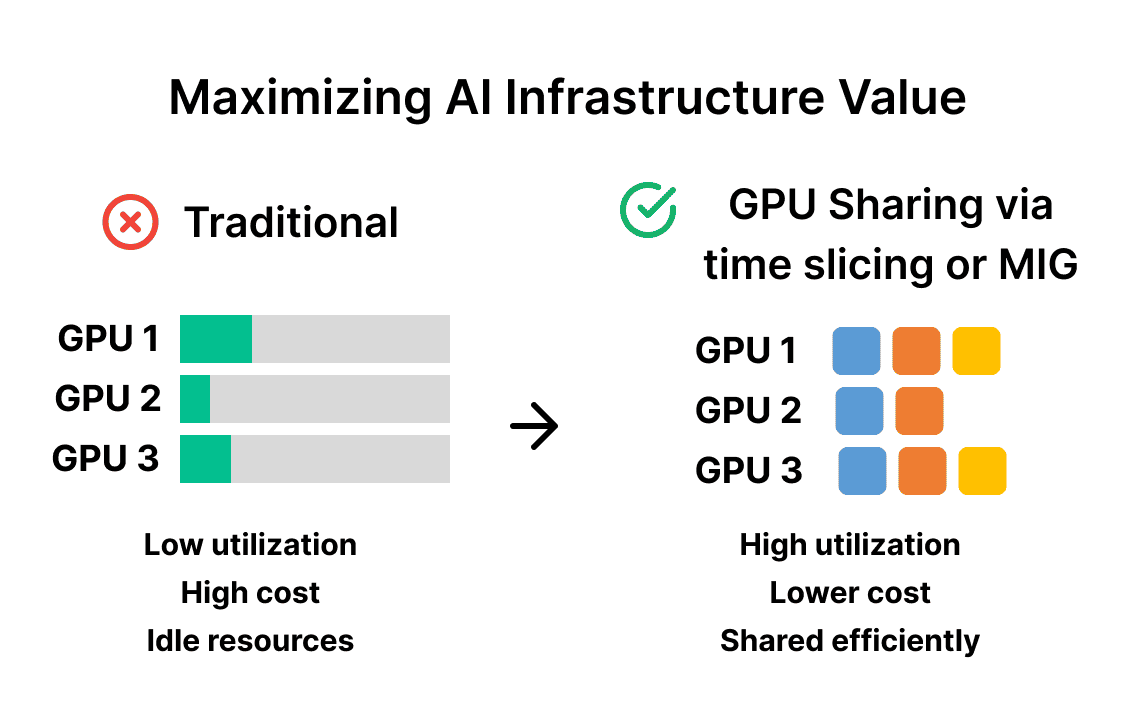
GPU Sharing: Two Powerful Approaches
Modern NVIDIA GPUs offer two distinct sharing mechanisms, each optimized for different business scenarios and use cases.
1. Time-Slicing: Democratizing GPU Access
Time-slicing enables multiple workloads to share a single GPU by dividing access into small time intervals. This approach maximizes utilization while minimizing complexity.
Key Benefits for Time-Slicing:
- Universal compatibility across all NVIDIA GPU generations
- Immediate cost optimization through improved resource utilization
- Simplified management with minimal operational overhead
- Flexible resource allocation that adapts to varying workload demands
Prime Use Cases for Time-Slicing:
-
Development and Testing Environments
- Multiple developers can simultaneously access GPU resources for model experimentation
- Continuous integration pipelines can run GPU-accelerated tests in parallel
- Research teams can prototype and iterate on AI models without resource conflicts
- Cost-effective environment for learning and skill development
-
AI Model Serving and Inference
- Deploy multiple model endpoints on shared GPU infrastructure
- Handle varying inference loads efficiently across different models
- Support A/B testing of model variants without dedicated hardware
- Enable cost-effective serving of lightweight models that don't require full GPU capacity
-
Batch Processing and Analytics
- Process multiple data pipelines concurrently during off-peak hours
- Run periodic training jobs and data preprocessing tasks
- Execute ETL operations with GPU acceleration
- Handle mixed workloads combining CPU and GPU-intensive tasks
2. Multi-Instance GPU (MIG): Enterprise-Grade Isolation
MIG provides hardware-level partitioning of high-end GPUs (A100, A30, H100) into completely isolated instances, each with guaranteed performance and dedicated resources.
Key Benefits for MIG:
- Hardware-level isolation ensuring complete fault and security separation
- Guaranteed performance with dedicated memory and compute resources
- Predictable SLAs for mission-critical workloads
- Compliance-ready architecture meeting strict regulatory requirements
Prime Use Cases for MIG:
-
Multi-Tenant SaaS Platforms
- Serve multiple customers on shared infrastructure with complete isolation
- Guarantee performance levels through dedicated resource allocation
- Ensure data privacy and security between different tenants
- Enable GPU-as-a-Service offerings with enterprise-grade reliability
-
Critical AI Workloads
- Run critical inference services with guaranteed response times
- Deploy multiple production models with isolated resource pools
- Ensure fault isolation where one workload cannot impact others
- Support mission-critical applications requiring consistent performance
-
High-Performance Computing
- Partition large GPUs for multiple simultaneous research projects
- Provide dedicated resources for long-running computational tasks
- Enable resource allocation based on project priority and requirements
- Support mixed workloads with different performance characteristics
Real-World Business Impact
AI Startup: Accelerating Innovation
A computer vision startup used time-slicing to enable their entire 15-person engineering team to access GPU resources simultaneously. Previously, developers waited hours for GPU availability, creating bottlenecks in their development cycle. With time-slicing, they achieved:
- Parallel development across multiple model architectures
- Faster iteration cycles reducing time-to-market by weeks
- Improved team productivity through eliminated resource contention
- Substantial cost savings compared to provisioning individual GPU instances
SaaS Provider: Enabling GPU-as-a-Service
A cloud platform provider used MIG to offer GPU instances to their customers with guaranteed performance and complete isolation:
- Multiple customer workloads on single physical GPUs
- SLA-backed performance guarantees for enterprise customers
- Improved profit margins through higher infrastructure utilization
- Competitive differentiation through flexible GPU offerings
Choosing the Right Approach
Time-Slicing is Ideal When:
- Cost optimization is the primary driver
- Workloads have intermittent GPU usage patterns
- You need maximum flexibility in resource allocation
- Development and experimentation are key use cases
- Operational simplicity is important
MIG is Essential When:
- Strict isolation is required for security or compliance
- You need guaranteed performance for SLA commitments
- Critical workloads demand predictable resource availability
- Enterprise-grade reliability is non-negotiable
Accelerate Your GPU Sharing Journey with Omnistrate
While the benefits of GPU sharing are clear, implementing and managing these strategies at scale requires sophisticated orchestration and automation. This is where Omnistrate transforms complex GPU resource management into a streamlined, enterprise-ready solution.
Why Omnistrate for GPU Infrastructure
-
Automated Resource Orchestration: Omnistrate automatically provisions and manages GPU sharing configurations across your entire infrastructure, eliminating the manual complexity of setting up time-slicing and MIG partitions. Your teams can focus on building AI applications instead of wrestling with infrastructure configuration.
-
Multi-Cloud GPU Management: Deploy GPU sharing strategies consistently across AWS, Azure, GCP, and on-premises environments. Omnistrate's unified control plane ensures your GPU resources are optimized regardless of where they're deployed, giving you true infrastructure flexibility.
-
Seamless Scaling and Automation: As your AI workloads grow, Omnistrate automatically scales your GPU sharing infrastructure, adjusting partitions and allocations based on real-time demand. This ensures optimal resource utilization without manual intervention.
-
Built-in Cost Optimization: Omnistrate's intelligent resource management automatically identifies underutilized GPU capacity and recommends optimal sharing configurations, helping you maximize the cost benefits discussed throughout this guide.
Transform Your AI Infrastructure Today
The GPU sharing strategies outlined in this guide become exponentially more powerful when implemented through Omnistrate's comprehensive platform. Instead of spending months building custom GPU management solutions, you can deploy production-ready GPU sharing infrastructure in days.
Ready to unlock the full potential of your GPU investments? Discover how Omnistrate can transform your AI infrastructure economics and accelerate your path to efficient, scalable GPU resource management.
For technical implementation details and configuration examples, see our complete GPU Slicing Documentation.