Introduction to Cloud Monitoring
Most people who work in platform engineering and cloud infrastructure are aware that you need to design both your applications and your underlying platform for high availability and fault tolerance, but there is a large range of resiliency from “relatively reliable” to “bulletproof”. The common adage goes something like this; for each “additional 9” of reliability, you’ll need to spend an exponentially greater amount of effort and cost to achieve it.
Why is this? And what goes into these additional levels?
My 20+ years of experience as a Sysadmin turned DevOps engineer turned SRE gives me the fortunate ability to see where a lot of these concepts and ideas both came from and how well they have (or have not) stood the test of time as we’ve progressed from traditional servers in the datacenter running monolithic applications to the current era of service-oriented architectures running on public or private clouds.
For over 5 years I designed and built custom-made servers for specific use-cases, whether they were optimized for storage density for a database server while I worked at Orbitz, extreme CPU clock speeds and ultra-low latency networking while working at a high-frequency trading firm, or low-cost high-memory private-cloud workloads while working at the ad-tech company Signal. At Confluent we always had to worry about high availability and extreme durability of the data held in each Kafka cluster, and as the leader of the cost engineering team I had to understand the key architectural tenets that gave Kafka its resiliency so we could continue to lower the costs without compromising any of them. Meanwhile at Citadel, the platform engineering team I was a part of provided a true multi-cloud architecture to our quants and developers so that we could leverage lower cost compute when and wherever it became available, as well as handle any individual instance failure without corrupting the computations or slowing them down significantly.
The overarching theme I’ve noticed over this time is that as we’ve progressed from managing more traditional servers in on-premise datacenters and the applications running on them to the modern public cloud ecosystem is one of ever-increasing complexity. What used to be accomplished with a few servers and a handful of auxiliary monitoring processes now requires knowledge of potentially hundreds of moving parts, spread across several different abstraction layers, all working in concert with each other. In this blog post I’d like to explore what we’re up against as cloud platform engineers and some of the more common techniques that are used in dealing with these reliability challenges.
What kind of failures will you need to design for?
Compute
Complete failures of servers have translated into failures of cloud VMs and k8s nodes, and these concepts map pretty much identically to each other, with the exception that it’s now easy and pretty fast to just get a new working VM vs the time it used to take to rack a new server or have someone in the datacenter replace it. I would also argue that due to the sheer scale of services now, both what you’re likely running and what the providers have to offer, failures of this type are more frequent than what we used to have to deal with on traditional hardware.
Thankfully since this is the most common failure scenario people prepare for, we have a lot of good tools in place for dealing with this, both at the hardware and software levels, and yet there are still nuances in handling this class of failures in a truly automated way to provide high availability.
You can think of this entire class of failures as “single instance unavailability” – and under this umbrella we’d include not just when the VM or server dies, it’s also when an application crashes hard due to something like running out of memory.
Process
Things get more difficult when trying to ascertain if a process is truly doing its job well enough to be considered healthy, especially if the reason a process can’t do meaningful work is due to an underlying resource being slower than usual. Another example of how process monitoring can be complicated is when any amount of work your process does requires a relatively long amount of time, such as longer than 10 minutes. This is relatively uncommon but not unheard of, especially in the realm of applications meant to work large queues of messages in batches. Finally, for data systems, there can be deadlatches causing the process to get stuck.
Larger-Scale Outages
Dealing with larger groups of servers failing simultaneously is even more difficult and generally increases the cost of solutions significantly. Often these time-correlated issues are related due to a common cause, such as a whole rack of a datacenter losing power or a common dependency going down, but this isn’t always the case; sometimes multiple issues really are just coincidences. I’ll go into more examples of these and strategies for dealing with them later.
Storage
One of the largest classes of failure concerns are related to disks; and now those can manifest a few different ways thanks to cloud offerings and advanced datacenter storage solutions. First of all, it’s important to look at the important differences between the common storage solutions offered in the public cloud, because properly handling failures for each one tends to be significantly different.
The disk offering that’s most like simply having hard drives or SSDs right in your servers are called instance stores, ephemeral disks, or local SSDs. These are typically cost-efficient and offer great performance, but do not offer any sort of additional durability or redundancy. Relying on these for critical data means dealing with data duplication at the application level. This is a great approach as long as the application is built with this additional level of complexity in mind, but for many purposes it’s better to use disk products designed to emulate network attached storage, such as EBS on AWS.
This group of block-storage products offer greatly increased durability over the ephemeral storage options as the volumes are backed by multiple physical devices, and they also provide the ability to be detached and reattached to different instances to give you nearly instantaneous access to your data again in the case of instance failure.
Another option for storage on the public cloud is object storage and other API-accessible storage products. S3 is the classic example and it offers significantly increased durability even over EBS (18 copies with erasure encoding vs. just 3 copies with two in the same zone!), as well as a lower cost per GB with a true pay-only-for-what-you-store pricing model. The primary reason for not wanting to use S3 is the additional latency in reading and writing the data, but the significant benefits mean that it is often used in conjunction with the aforementioned block storage products.
Even with all these options available to you, all the failure modes you’re going to need to consider still fall under two general categories; availability and durability. For your availability concerns, you’ll need to make sure that you have thought through what will happen both when you lose a disk or access to one of these storage services but also when they switch to a different availability mode, such as a volume suddenly going read-only. Since you can’t really do anything to prevent complete loss of access to a service as big as S3, the SLAs regarding availability are not as high as you might initially think.
For durability, you’ll need to come up with your own solutions while using instance storage and EBS, and the specifics of your designs will need to be tailored to each of your applications’ needs. An additional complication some companies opt for is striping and/or mirroring local disks or EBS volumes to increase performance or redundancy with RAID or other volume management software, but that doesn’t mean you can ignore the other safety mechanisms discussed already. Object storage services on the other hand tend to offer excellent durability guarantees, but as always, with your most critical data, you’ll still want to ensure appropriate precautions have been taken.
Networking
Networking issues unfortunately are among the most common and hardest to deal with issues in the datacenter and cloud. From what I’ve experienced, while we’ve certainly come a long way from the days when critical networking equipment would simply start failing and causing mass outages, now it’s more critical than ever to pay close attention to application architecture, and health-check rules, as well as your policy design, api-rate limits & management of both.
At the intersection of the critical requirements of security, cost-efficiency, and performance lies the design of your network. As an example, let’s consider a simple service behind a load balancer hosted in a few availability zones for redundancy. There is also a distributed database which each instance of the application needs to be able to access, and to save money, the service has been designed to keep both the traffic between the load balancer and the application servers, and the app servers and the DB within the same zone.
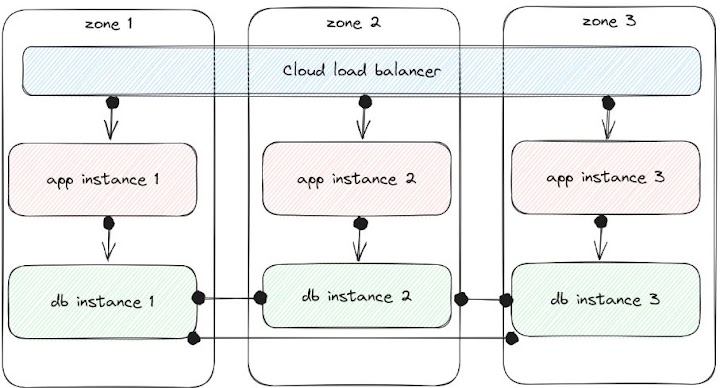
When an entire availability zone becomes unavailable (zone 1 in this example), the goal is to have traffic continue to work in zone 2 and 3 against DB instances 2 and 3:
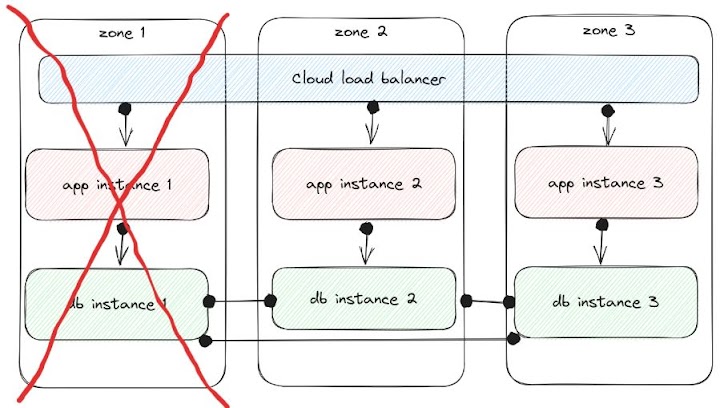
However, this only works if the healthchecks and total system state allow for it; with kubernetes, ELB health checks, DNS provided from a different service, and potentially one of these other storage services actually backing the database, there are many aspects to consider to really make this work the way you want during large-scale failures. If the data in each database is a full copy, then you should be able to continue without much of an interruption in service; you’d just need to spin up additional capacity in the two zones that are still operational to make up for the loss of the first. But in the case where the data is sharded among the db instances, if one db instance can no longer communicate with the other two instances, you can only ensure that you’re still serving up accurate information to the app layer if the healthchecks are testing their apps for data that was served by the specific instances they can still connect to. In this case, since the data is partially replicated between the three db instances, then an entire zone going unavailable should kick off a rebalancing operation to return redundancy. As with many of these sorts of issues, this really will come down to application design and chaos testing more than the capabilities of the platform you’re running on.
Another area I mentioned earlier about networking issues is tricky because it only manifests as a networking problem after the root cause has already begun, sometimes significantly earlier, and that’s the problem of VPC and DNS API rate limits. When you’re fully in control of your own networking hardware, generally speaking this isn’t as much of a problem, but in the public cloud, some of the most critical networking services you’ll be working with enforce strict global rate limits to not just changes but also in some cases lookups.
See you next time...
In our next post, we’ll cover additional complications you’ll likely see in each of these areas and some of the most common strategies for dealing with them.