Scaling - it’s the reason we’re all using this cloud thing anyway, right? Surely all of your applications have been tested to effortlessly scale from 0 to 1,000 in milliseconds, and your databases can rebalance after scaling within minutes with zero impact to anything important, correct?
Don’t worry, I don’t think anyone has fully cracked this nut. But why is this? What makes it so difficult to actually get ALL the benefits of the infinitely flexible cloud?
Before we dive into that quagmire, let’s be good scholars and take a step back and look at what the history on the subject can teach us and where we’ve come since then.
A Trip Down Memory (and Compute) Lane
Ye Olde Vertical Scaling
Early in the days of commercial computing, the software businesses wanted to run was generally custom-designed for the machine(s) they were going to be purchasing. This was before my time but I’ve heard plenty of stories about how rigid the enterprise-grade computing hardware was back then. Software would be designed for the particular machine you had / were going to get, and these computers would be designed to last for many years doing only a small number of operations, programmed in funny ways involving punch cards or paper tape.
I think the main thing we should take away from this era is that when you wanted to be able to handle more traffic or get more performance, you had to undertake an absolutely massive migration to a brand new computer, which would probably be most akin to re-building your entire tech stack these days. Furthermore, if there was any parallelism in action in businesses using machines like these, it was likely only happening on the level of processing multiple programs using multiple million-dollar computers.
Mixed Scaling in the Traditional Data Center
My first professional job outside of college was at Orbitz, and they had two traditional data centers in the Chicagoland area for all their computing needs. I was there for just over 5 years, and over that time I got to witness several large and many small migration efforts to newer hardware (and even got to purchase a couple of our old servers for personal use - the aughts were a wild time 🙂).
These migrations were almost always herculean efforts; requiring many teams of a dozen or more engineers to put in many extra hours customizing applications, pouring over configuration files, and hand-turning shell scripts. I worked in the NOC (Network Operations Center) and we’d perform these migrations in the middle of the night, usually early Saturday morning when traffic to the site was lowest.
What sticks out to me now about the way we approached this work back then was that there simply wasn’t enough consistency between one massive migration and the next. New server hardware or software was coming so regularly that we had to adapt huge swaths of the tech stack rapidly to the changing ecosystem. Why were we going through all these changes if they were so difficult? Well, to scale of course! Traffic to the site was basically always increasing while I was there, and the complexity of queries generated by the ever-improving front end to the backend kept growing as well. This meant that simply handling the same amount of traffic from one month to the next was not an option, and even if we just continually moved everything to newer servers we wouldn’t keep up.
When the databases were overloaded (which was pretty often the case), we had to resort to creative solutions until we could afford (both in time and money) a database migration. These were mostly Oracle servers and if I recall correctly they were quite monolithic in nature. When you wanted more throughput, you needed more cores, ram, and IOPs all on the same large server. This is what most of us think of when “vertical scaling” is mentioned - going from, say, 8 cores and 32 GB of ram to 16 cores and 32 GB of ram - for the same (often singular) application. Since all write operations to the old database instance had to be stopped before the replication to the newer instance could be finished, we would perform these migrations during maintenance windows where we’d literally just close the website for hours at a time.
As you can imagine, all sorts of things could go wrong during these events, and more than once what should’ve been a routine operation turned into an extended site outage. It wasn’t always the database vertical scaling that caused this, either. Plenty of our applications and caching systems were designed to be horizontally scaled, but almost all of these scaling operations had to be performed during similar downtimes. I remember one time we literally doubled the already massive Tangosol cache cluster - only to have it fail to work correctly at the new size. This was a classic example of not testing what we wanted production to look like in a pre-production environment, but to be fair to us, there was literally no physical way we could run the same number of machines anywhere except production at the time.
Virtual Machines
When virtual machines started getting more popular, companies suddenly had the ability to turn their 100 64 GB servers into 800 8GB ‘servers’ - and for many, many applications this is a huge win. This gave rise to two separate but equally impactful improvements in the area of scaling; rapid vertical scaling and significantly more parallelism for horizontal scaling headroom.
Pretty quickly companies with lots of extra computing capacity came up with a great idea of what they could do with all of that power just sitting around unused…
HyperScalers, Cloud, and Containers
Amazon definitely wasn’t the first company to offer up their extra computing capacity in the form of rentable virtual machines, but their ingenuity to put that ability behind APIs that gave you access to the machines within minutes is what really defined the beginning of the cloud to most.
Suddenly, this meant we had a whole new dimension available to scale into - if your on-premise VM environment was totally out of capacity, just pay a few cents per hour to run them somewhere else!
I’m sure many readers of this will only know of using the cloud as ‘the only place we even need compute anymore’, but for many companies both back when the cloud was new and even now this flexible capacity is still the best part about infrastructure as a service. Plus, you have not only the ability to horizontally scale by adding more VMs, you can simply recreate the cloud instances as larger and larger types to vertically scale as well. So what’s the catch here? Well, the cost for one; if you’re already deeply invested into running your own data centers, each additional VM running in the cloud is that much harder to justify. There is also the complexity to consider - I worked on some tooling at Signal which let us use our meager on-premise server farm running openstack the same way we leveraged Rackspace’s cloud and AWS, and while it did the job, there were many, many inconsistencies that we had to continuously test and account for to keep our infrastructure configs working the same way in each environment.
The Common Themes
A few constants regarding scaling challenges have remained basically unchanged throughout all these eras.
- Vertical and horizontal scaling are both useful; they just need to be used appropriately
- Scaling stateless applications is significantly easier than scaling your stateful services
- There is value at all levels of scaling investment: manual, semi-automated, and fully automated
- Getting an accurate measure of load is necessary for autoscaling and can be tricky
- More than anything else regarding scalability, the cloud offers elasticity
- If you can’t scale down, you’re going to be massively overprovisioned the majority of the time
Let’s go into each of these in a bit more detail.
Vertical vs. Horizontal Scaling
Whether you’re just taking your database instance from an r5.4xl to an r5.8xl or physically adding more memory to a rack-mounted server, vertical scaling has been the to-go method for adding capacity for decades. It’s easy to see why; the benefits are immediate and simple to understand. But the double-edged sword of vertical scaling has a nasty downside, and it’s the hard limit(s) that you will assuredly hit eventually. Not to mention the disproportionate increase in costs as you splurge on premium hardware.
Basically, this is why parallelism and horizontal scaling came to be in the first place; eventually you need more machines to handle more load. While this is relatively straightforward for stateless applications, the same can not be said for your databases and other stateful systems.
Stateful vs. Stateless Scaling
Let’s look at the simplest kind of stateless application - imagine you wanted to build an online calculator that just took some user input in the form of an equation. Our stateless application just takes this input then calculates and returns the result. It’s pretty easy to see how this can scale indefinitely by simply adding more servers to run your application, assuming your load balancing game is up to snuff.
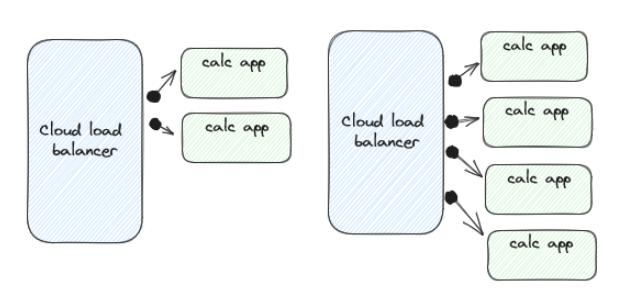 Simple Horizontal Scaling Example - if only everything was this easy!
Simple Horizontal Scaling Example - if only everything was this easy!
Some of the current technologies you could leverage to achieve this include elastic load balancers, autoscaling groups, and kubernetes’ horizontal pod autoscaler. Most of the time, these solutions will deliver satisfactory results, but you need to make sure you’ve carefully selected your scaling metric and tuned the values to match real-world load scenarios. This is so important in fact there’s another section about it below!
Other gotchas you’ll have to look out for include ensuring you have the available IP space in your VPC and subnets (have been caught with this problem at uncomfortable times more than once!), ensuring your load balancer configurations are correct (the cloud LBs are really good at this, thankfully), and ensuring you’re using a sufficient healthcheck / readiness probe to know when it’s safe to send traffic to the new instances.
But if you extend this example to one where users can store their sessions, including previous calculations, custom formulas, and other state, then we need a way to scale out the storage as well.
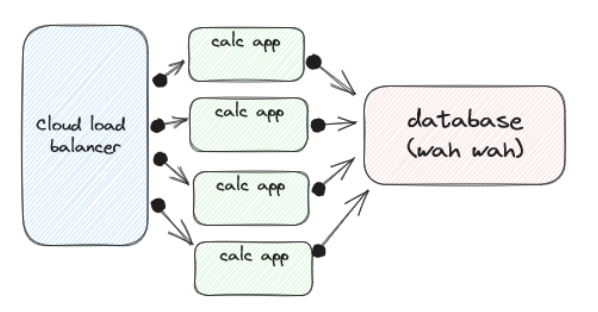 Why do we always have to ruin perfectly good simple architectures with databases?
Why do we always have to ruin perfectly good simple architectures with databases?
It’s certainly an exciting time to an engineering in this space - there seems to be a sort of renaissance in database designs right now - but as advanced as some of these new systems are, it still doesn’t mean every problem regarding scaling is automatically solved for you. For one, these kinds of databases are much harder to scale down than stateless apps, as you’ll need to ensure all the data is moved off of any node you want to turn down first. Another challenge is ensuring new traffic to fresh nodes doesn’t overwhelm the cluster if it’s already in the midst of rebalancing operations or similar. Lastly, you’ll need to find the right balance of horizontal and vertical scaling for your stateful apps, and this is best accomplished through rigorous testing and experimentation with representative traffic and data loads.
Value at Every Investment Level
We had a very manual horizontal scaling procedure at Signal, and we typically scaled up right before big shopping times like Black Friday / Cyber Monday, then back down the following Wednesday through Friday. What stuck with me about all this work was that if we hadn’t done it, we would’ve needed to run almost twice as many machines all year long as we did for just that one week.
This is a good example of what I mean when I say there’s good value in investments into scaling even if you’re not fully automating everything. Chances are this isn’t news to anyone, but hopefully it’s a reminder that even if you only have some automation in place, you should be proud of that.
Taking your systems to the next investment level is typically a good idea, but you should still perform an analysis of how often you expect to scale and how difficult the work will be to make sure it’s worth it.
How to Measure Load
If you do want to take your applications to fully automatic scaling, you’ll need to have fantastic load measurement systems in place. Typically, CPU utilization and memory usage are the most closely monitored metrics but it’s important to understand how additional resources will be utilized. In ideal scenarios, as you handle more traffic, your load metrics will simple increase linearly. But something I’ve witnessed first-hand that makes this much harder to deal with in practice is when an application will use much more memory or CPU for particular, uncommon operations. One example of this was a function triggering a massive in-memory cache invalidation which spiked our load metric inadvertently. Another time we had individual user operations which could actually trigger memory utilization to climb on all of the instances running our main application.
Going into the details of observability and how to get these measurements is beyond the scope of this article but the most helpful piece of advice I can summarize here is to artificially scale your systems in pre-production to as extreme of limits as you would ever reasonably expect, and then try to find the breakpoints. Did you run out of CPU first? Memory? Did you make sure you tested all your app’ endpoints? Even the uncommon ones? With some decent representative datasets loaded up? Which metrics were most closely correlated with the increase in traffic? If you didn’t find any good ones, chances are you need to keep instrumenting your applications and servers until you do.
Elasticity in the Cloud
After everything else discussed already, hopefully this is obvious, but it’s so important it bears repeating: If you’re using the public cloud, try to make sure you’re only paying for what you use. If you’re running many, many instances and the CPU and Memory utilization are both very low, spend the time to figure out why.
This was a massive part of my primary job at Confluent while leading the cost engineering team. We would generate detailed reports about which pods were running where, how many resources they were using, and correlate that back to why our control plane had scheduled them in this manner. We constantly found potential optimizations, and this was after you took into account scaling in the common sense of only running the minimum number of services to ensure fault tolerance. When you add kubernetes into your tech stack buzzword soup, you really need to pay attention to how you utilize namespaces, nodepools, and even entire clusters to make sure you’re not committing too many resources to minimum thresholds.
For example, it sounds pretty reasonable to say something like “Every k8s cluster in our fleet has an acme-system namespace where we run the basic security and fleet management services required for standard operations and compliance”. But if those services have heavy or specific resource requirements that don’t allow their pods to binpack on nodes running services in other namespaces, you will likely find yourself in a situation where each new k8s cluster has an unreasonable cost footprint.
Scaling Down
Generally speaking, the even harder aspect of achieving elasticity is not scaling up, but scaling back down.
If you’ve already added shards/partitions/etc to your parallelized database as you grew it from 8 to 16 nodes, and now you’ve survived the holiday rush and want to scale back down to 8 nodes, you have to cram the same larger number of shards onto half the instances. Thankfully, there have been significant advancements in the industry of massively parallel databases and if you choose the right system this might all be handled for you. But if you’re designing something yourself or running an older system that you can’t change, you’ll need to pay close attention to the tools given to you to make scaling down a possibility.
The sad truth is that many systems still don’t even allow you to scale back down, so be sure to do your research before scaling up in the first place. I’m reminded of all the times we increased the size of our elasticsearch clusters to handle temporary slowdowns in log ingestion rates due to noisy application logs; if we had simply dealt with the applications’ noise instead, we could’ve delayed those expensive expansions for potentially years, savings an absurd amount of money.
What’s Next?
One of the more exciting developments in the area of scaling is the promise of serverless systems. In essence, these are just efficiently-designed infrastructure systems where the service provider is willing to foot the bill for the constant infrastructure costs while customers can pay only for individual slices of usage.
Unfortunately, the term serverless is already overloaded, and while one of the first types of products that popularized it’s usage is AWS’s Lambda, which lets you pay per invocation of code functions, there are now thousands of examples of a very different kind of serverless including stateful systems such as BigQuery, CockroachDB, and AWS Aurora. Make no mistake though, just because something might be called serverless doesn’t mean it’s designed or built the same way. Making stateful systems like Kafka into a serverless offering is a massive undertaking considering the technology itself expects long-lived persistent TCP connections. This is in stark contrast to any technology which can have easily quantified discrete units of usage which stem naturally from the standard methods in which the application is accessed.
Whether you’re trying to implement and offer your own service in a serveless fashion or you just want to benefit from using existing offerings, the benefits for this type of offering are outstanding, especially at low-volume use-cases. Just beware of the costs involved with using these; you’ll want to run the numbers to see how your usage’s costs will scale to be prepared for the point where it makes sense to switch to traditional provisioned capacity.
As a service provider however, it’s a great time to design and build data systems that can be offered as a serverless product. We’ll explore how Omnistrate can help you do exactly this in a future post.