Every quarter, platform engineering teams face the same recurring question: What broke this time that has nothing to do with our product?
Over the past several quarters, the answer has been relentless. OS deprecations. Kubernetes version sunsets. A historic spike in CVEs driven by the AI boom. End-of-life open source components. Each one consuming engineering cycles that could have gone toward shipping features, closing deals, or improving the customer experience.
If you had been running on Omnistrate, none of it would have been your problem.
This is not a hypothetical. This is a concrete accounting of the infrastructure tax that consumed engineering organizations industry-wide — and how a managed control plane eliminates it entirely.
The Quarterly Infrastructure Tax: A Real Accounting
Amazon Linux 2 end of life
In 2025, AWS officially ended standard support for Amazon Linux 2 — the operating system underpinning millions of EC2 instances and EKS nodes. Organizations that had not migrated to Amazon Linux 2023 faced a choice: pay for extended support or execute a forced migration across their entire fleet.
For teams managing dozens or hundreds of node groups, this was not a weekend project. It meant rebuilding AMIs, re-validating application compatibility, updating launch templates, testing networking behavior, and coordinating rolling replacements — all while keeping production stable.
GCP and Azure image and version deprecations
Google Cloud and Azure followed similar patterns. GKE deprecated older node image versions on aggressive timelines. Azure AKS sunset Kubernetes versions with mandatory upgrade windows that left teams scrambling to validate compatibility.
Each deprecation triggers the same cascade: test the new version, verify workload compatibility, update Terraform modules or IaC manifests, coordinate the rollout, and hope nothing breaks in production. Multiply that across multiple clusters and multiple clouds, and you have a full-time job that produces zero customer value.
Kubernetes version upgrades: the never-ending treadmill
Kubernetes releases three minor versions per year. Each version is supported for approximately fourteen months. That means every organization running Kubernetes must upgrade at least once — often twice — per year to remain on a supported version.
A Kubernetes upgrade is never just a control plane version bump. It cascades into:
- API deprecations — Resources you relied on may no longer exist in the new version
- Add-on compatibility — CoreDNS, kube-proxy, CSI drivers, ingress controllers, and CNI plugins all need version-matched updates
- Application behavior changes — Subtle changes in scheduling, networking, or storage behavior can surface latent bugs
- Node pool recreation — In many managed Kubernetes services, upgrading node pools requires draining and replacing nodes
For organizations running multiple clusters across regions or clouds, this becomes a multi-week effort repeated every six to nine months.
The CVE tsunami driven by AI adoption
The rapid adoption of AI infrastructure has introduced an unprecedented volume of security vulnerabilities into the ecosystem. As organizations rushed to deploy GPU clusters, inference endpoints, and ML pipelines, they pulled in complex dependency trees — CUDA drivers, container runtimes optimized for GPU workloads, model-serving frameworks, and custom networking stacks — each expanding the attack surface.
Consider the reality of recent quarters:
- Ingress-NGINX CVE-2026-4342 — Yet another comment-based NGINX configuration injection vulnerability in ingress-nginx, continuing the pattern of IngressNightmare from 2025. Organizations barely recovered from the first wave before needing to patch again.
- CSI Driver path traversal (CVE-2026-3865 / CVE-2026-3864) — Path traversal vulnerabilities in CSI drivers for SMB and NFS that could delete unintended directories on file servers. Any cluster using network-attached storage required immediate remediation.
- Ingress-NGINX auth-url protection bypass (CVE-2026-24513) — A bypass of authentication protection in ingress-nginx, paired with multiple additional injection vulnerabilities (CVE-2026-24512, CVE-2026-1580), exposing clusters to unauthorized access.
- Ingress-NGINX admission controller DoS (CVE-2026-24514) — A denial-of-service vulnerability in the admission controller that could be exploited to disrupt cluster operations.
- CoreDNS ACL Bypass (CVE-2026-26017) — A TOCTOU flaw in CoreDNS plugin execution order that allows attackers to bypass DNS-based access controls in multi-tenant clusters, exposing restricted internal services to unauthorized discovery.
But it is not just infrastructure-level CVEs that consumed engineering teams. Critical application dependencies — the libraries and frameworks your product actually runs on — faced their own wave of urgent vulnerabilities:
- OpenSSL CVE-2024-9143 — A low-level cryptographic vulnerability affecting virtually every TLS-terminating service. Teams had to audit every container image for affected OpenSSL versions and rebuild across their entire fleet.
- Apache Log4j follow-on patches — Years after the original Log4Shell disclosure, organizations were still discovering unpatched instances in transitive dependencies, requiring repeated emergency scans and updates.
Each of these demanded the same firefighting pattern: an urgent Slack thread at 2 AM, engineers pulled off feature work, hastily assembled rollout plans, compressed testing cycles, and deployments pushed to production under pressure. The toll is not just the hours spent — it is the accumulated fatigue, the shortcuts taken under duress, and the regression risks introduced by rushed patches that were never given proper validation time.
Deprecation of open source tooling
The open source ecosystem moves fast, and projects that were standard choices two years ago are now deprecated or fundamentally restructured.
Kubernetes Dashboard is a clear example. Once the default observability tool bundled with every cluster, it was deprecated from the core Kubernetes project. Organizations relying on it had to migrate to alternatives — Headlamp, Lens, or custom Grafana dashboards — while also addressing the security implications of running an unsupported component with cluster-admin access.
Similarly, Helm v2 (and its Tiller component) reached end of life, and the Docker container runtime was deprecated in favor of containerd. Each deprecation required engineering effort that delivered no new capability — only maintained the status quo.
The Hidden Cost: It Is Not Just About Money
The obvious cost is engineering time. But the deeper cost is opportunity cost — what your team did not build, ship, or sell because they were patching OS images and upgrading Kubernetes versions.
Velocity loss
Every quarter spent on infrastructure maintenance is a quarter not spent on product differentiation. Your competitors who are not managing this burden are shipping faster.
Cognitive load
Platform engineers carrying the mental overhead of tracking deprecation timelines, CVE disclosures, and version compatibility matrices have less capacity for creative problem-solving and architectural innovation.
Risk accumulation
Teams that defer maintenance due to competing priorities accumulate technical debt that compounds. A skipped Kubernetes upgrade makes the next one harder. An unpatched CVE becomes an audit finding. Deferred OS migrations become emergency projects when extended support expires.
Talent drain
Senior engineers do not want to spend their careers patching infrastructure. Organizations that cannot offer meaningful product work lose their best people to companies that can.
What Omnistrate Customers Experienced Instead
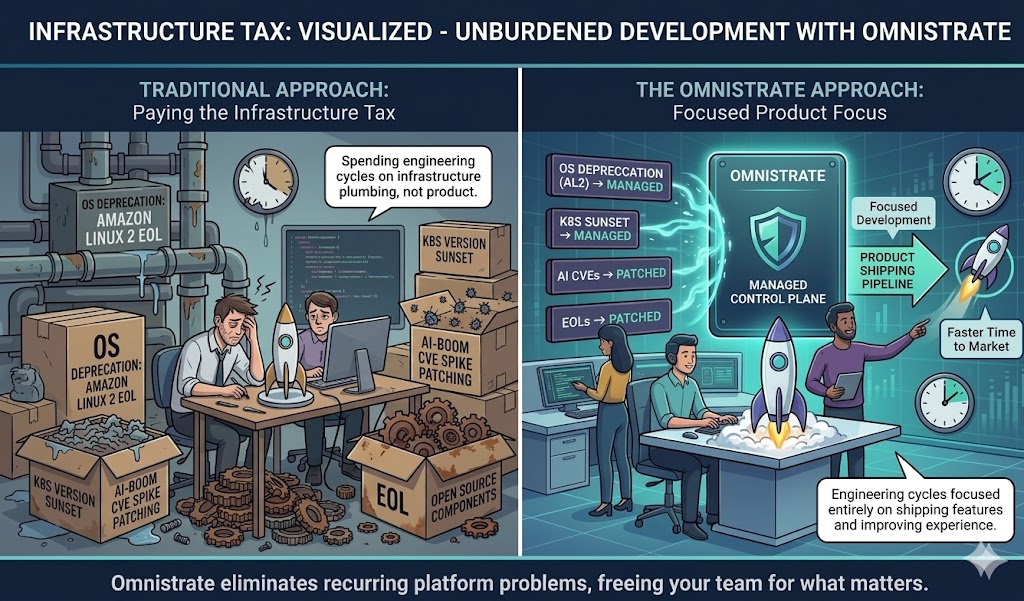
While the industry scrambled through these quarterly fire drills, Omnistrate customers experienced something different: nothing happened. Their infrastructure stayed current, secure, and compliant — automatically.
Automated OS lifecycle management
When Amazon Linux 2 reached end of life, Omnistrate-managed infrastructure was already running on supported OS versions. The migration happened transparently, validated automatically, and rolled out with zero customer action required.
Continuous Kubernetes currency
Omnistrate maintains Kubernetes version currency across all managed deployments. Version upgrades are tested, validated, and rolled out following proven patterns — including API compatibility checks, add-on version alignment, and progressive rollouts with automated rollback.
Your team never sees a "mandatory upgrade deadline" email. The platform handles it.
Fleet management and CVE patching
Omnistrate provides tools to easily manage and patch your entire fleet. When a CVE is disclosed, you fix the vulnerability in your container image, push a patch version, and roll it out to all your customers from a single control plane — no need to coordinate individual upgrades across dozens of deployments.
No emergency war rooms. No weekend patch sprints. No customer-by-customer rollout coordination.
Dependency and tooling lifecycle
Deprecated components are identified, replacements are validated, and migrations are executed as part of ongoing platform maintenance. When Kubernetes Dashboard was deprecated, Omnistrate customers already had purpose-built observability through the platform — no migration needed.
Reclaiming Your Engineering Capacity
The infrastructure tax is real, it is recurring, and it is accelerating. The cadence of deprecations is not slowing down. The volume of CVEs is increasing as AI expands the attack surface. Kubernetes continues its rapid release cycle.
You have two choices:
-
Continue paying the tax — Dedicate senior engineers to a perpetual cycle of patching, upgrading, and migrating infrastructure. Accept the velocity loss and opportunity cost as a cost of doing business.
-
Eliminate the tax entirely — Let a purpose-built control plane manage infrastructure lifecycle, security patching, and version currency while your team focuses on what actually differentiates your business.
Omnistrate exists to make option two real. Not as a future promise, but as a production-proven platform that has already navigated every one of the challenges described above — transparently, at scale, across multiple clouds.
Your platform engineers have better things to do. Talk to us about reclaiming your team's capacity and eliminating the infrastructure tax — permanently.